


Reportatge
Darrere l’algoritme: així es crea una IA
Què són els algoritmes i els models d’intel·ligència artificial, qui els dissenya i desenvolupa i quins processos se segueixen per ...
 Als conjunts de dades d’entrenament s’hi aprecien els biaixos de qui selecciona les dades (Pexels).
Als conjunts de dades d’entrenament s’hi aprecien els biaixos de qui selecciona les dades (Pexels).
Compartir
per Esther Paniagua
04/01/2024
Què són els algoritmes i els models d’intel·ligència artificial, qui els dissenya i desenvolupa i quins processos se segueixen per implementar-los i governar-los?
Diu ChatGPT que els algoritmes són “els arquitectes silenciosos de la nostra vida quotidiana”. És una bona metàfora, que transmet com aquestes fórmules regeixen no només la nostra vida digital, sinó bona part de les nostres interaccions i processos analògics i híbrids. El seu poder rau en la ubiqüitat i influència. I sovint, en la invisibilitat.
Fins a l’arribada de la intel·ligència artificial (IA) generativa aquest concepte encara era un gran desconegut. Però fins i tot ara que ja s’ha colat al nostre vocabulari, no entenem què són ni què hi ha darrere dels anomenats algoritmes. Qui els dissenya i quin és el procés de creació, implementació i govern?
El què
Un algoritme és un conjunt de regles matemàtiques que ajuden a calcular la resposta a un problema o a fer una tasca específica. N’hi ha de més sofisticats i de menys, i els d’intel·ligència artificial només en són un subtipus (n’hi ha molts d’altres). Per exemple, un algoritme d’aprenentatge automàtic -que és una tècnica d’IA- consisteix en una sèrie d’instruccions que s’executen en conjunts de dades (datasets) per reconèixer-hi patrons.
Alhora, un model d’intel·ligència artificial és el resultat d’entrenar un algoritme amb aquest dataset. O dit altrament: un algoritme és el que es fa servir per entrenar un model. Funciona com un programa al qual se li facilita una entrada i en proporciona una sortida. El programa serà diferent tant si es canvia el dataset (encara que s’utilitzi el mateix algoritme) com si es canvia l’algoritme (encara que es facin servir les mateixes dades).
En què consisteix això d’entrenar un algoritme? Doncs bàsicament en alimentar-lo amb dades i en retroalimentar-lo per crear i millorar les regles del model. És una tasca que en models grans com els de la IA generativa pot representar milers d’hores de feina. L’objectiu és ensenyar a l’algoritme com seria el resultat ideal, és a dir, quina sortida s’espera per a cada tipus d’entrada, de manera que pugui oferir prediccions millors. Aquestes prediccions poden variar: categoritzar imatges, interpretar el significat de frases, etc.
Per exemple, ChatGPT Plus es basa en el model GPT-4, la quarta generació dels anomenats grans models de llenguatge (LLM en anglès), capaç de processar entrades en forma d’imatges i de text, i de generar sortides de text. Aquest LLM -simplificant molt- es basa, alhora, en diversos tipus d’algoritme: de processament de llenguatge natural i d’imatge, de traducció, de generació de text, etc. Pel que fa al dataset, s’estima que aproximadament conté un petabyte de dades (uns 300 milions de fotos digitals de qualitat raonable) o fins i tot diversos petabytes.
El treball d’entrenament normalment el duu a terme un científic de dades, que en una analogia esportiva podria ser l’entrenador d’un atleta (l’algoritme) a partir de dades com els registres de rendiment anteriors, el règim, etc. (el conjunt de dades emprat).
Les dades que es fan servir poden estar etiquetades o no. Les primeres contenen anotacions amb paraules que n’identifiquen les característiques, propietats, classificacions o objectes específics. Per exemple, a la categoria animals, les imatges es poden etiquetar com a gossos, gats o ocells. Les dades no etiquetades són just el contrari, i l’absència d’etiquetes obliga el model a avaluar cada ítem segons les seves característiques, com ara el color i la forma.
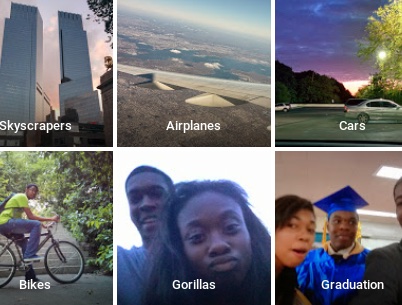
Totes aquestes tasques són cabdals per a la precisió d’un sistema. Un mal entrenament, un mal etiquetatge i un mal conjunt de dades poden comportar errors tan mediàtics com el del sistema de visió artificial que va seguir la calba de l’àrbitre en lloc de la pilota en un partit de futbol l’any 2020. O com el fallit algoritme de Google Photos, que va etiquetar com a “goril·les” la programadora Jackie Alcine i un amic (tots dos afroamericans). Va passar el 2015 però el problema persisteix, tal com va revelar una investigació recent de The New York Times.
El qui (inventa)
Els cervells darrere d’aquests algoritmes poden venir de les matemàtiques, la informàtica, la física… i, al contrari del que se sol pensar, no són els programadors. “Normalment són investigadors que estan en procés de doctorar-se o que ja s’han doctorat”, explica Ariadna Font, exdirectora d’enginyeria de la plataforma d’aprenentatge automàtic de X (quan encara es deia Twitter).
“Per aconseguir desenvolupar una cosa que sigui eficient i que funcioni millor que el que ja hi ha, cal dissenyar molts experiments amb una metodologia molt específica que requereix aquest tipus de preparació, i el resultat de la qual es publica en una revista científica”, detalla Font, que ara està creant una empresa -Alinia- que té com a objectiu que les organitzacions puguin fer servir models LLM de codi obert de manera fiable i responsable.
Aleshores, què fan els desenvolupadors o enginyers de programari? “Es dediquen a mirar d’optimitzar els algoritmes i models que ja s’han descobert, així com a implementar-los”, assenyala l’experta. És un treball col·laboratiu. En una plataforma com X hi ha persones treballant en aspectes diversos, que a més impliquen centenars i fins i tot milers d’algoritmes i de models.
“L’algoritme que et permet veure notificacions al telèfon és diferent del que te les envia al correu electrònic. Aquests, a més, poden aprendre, adaptar-se i evolucionar. És un sistema molt complex”, apunta Font. De fet, només els algoritmes per a sistemes de recomanació (com els de les xarxes socials, cercadors, plataformes de streaming, etc.) són un món per si mateixos, amb conferències anuals que reuneixen milers d’investigadors a escala internacional per resoldre els reptes més urgents en aquest àmbit.
El com: el cas de Hugging Face
Quin procés se segueix des que s’inventa o es concep un algoritme fins que s’engega, s’implementa i s’allibera al món? Qui hi intervé? Les possibilitats són tantes com el tipus d’organització. Explorem el cas de l’empresa Hugging Face -que ha desenvolupat diversos models LLM de codi obert- amb l’exassessor d’Afers Tècnics i Regulatoris, Carlos Muñoz Ferrandis.
El primer que cal explicar és que, a diferència del model tancat d’OpenAI amb GPT-4, l’aproximació de Hugging Face amb els projectes BigScience o BigCode és oberta. “En un projecte d’aquest tipus la comunitat es reuneix i posa en comú esforços, tant per al desenvolupament com per a la governança del model”, explica Muñoz. Aquesta comunitat és un conjunt de persones que contribueixen de manera voluntària al projecte. També poden estar patrocinades per Hugging Face o per altres empreses o institucions de recerca (per exemple, l’Alan Turing Institute, al Regne Unit).

Què comprèn el desenvolupament d’un model? L’expert -soci de Font a Alinia- explica que aquest procés inclou la recol·lecció de dades per a l’entrenament, el disseny de l’arquitectura, l’entrenament del model i altres etapes anteriors a la posada a disposició del públic el repositori obert.
Aquest tipus de projecte es divideix en diferents grups de treball, que essencialment són quatre: el de dataset, el d’entrenament, el d’avaluació i el de governança. En el cas de BigCode, la tasca del primer equip –format per empleats de Hugging Face i de ServiceNow– era construir el conjunt de dades previ a l’entrenament. Va involucrar dues persones a temps complet i una tercera per dur a terme una tasca de processament anomenada “deduplicació”. A més, deu persones més (xifres aproximades) es van encarregar de crear conjunts de dades addicionals, alguns amb dades personals, seguretat, exclusió voluntària, etc.
Al segon grup, el d’entrenament (que entrena l’algoritme i el model, com s’explica més amunt en aquest article) hi van participar entre quatre i sis persones, també de Hugging Face i de Service Now. Treballaven en l’entrenament i l’arquitectura del model. “L’objectiu era combinar tots els avenços actuals i assegurar-nos que podríem fer aquesta feina tan ràpidament com fos possible”, assegura Muñoz.
L’equip d’avaluació, format per entre cinc i deu persones, va participar per establir quines són les bones mètriques i punts de referència per avaluar l’algoritme i el model final, amb molts punts de control per facilitar la feina.
Finalment, el grup de governança, que fins fa uns mesos liderava el mateix Muñoz. Es va encarregar de desenvolupar els mecanismes per governar el model, en el marc de l’entrenament i a l’hora de posar-lo a disposició al públic. Aquest procés va incloure la redacció dels termes d’ús del model, els mecanismes tècnics de filtres de dades personals, la llicència, etc. L’equip, format per una vuitena de persones, va treballar en paral·lel al desenvolupament del projecte des del principi i fins al final. Un procés així pot durar uns set-vuit mesos, com va ser el cas de Big Code.
Durant tot aquest procés, l’equip de Muñoz va publicar tres documents clau. Un és la Carta de governança, que descriu els diferents mecanismes i àrees de governança del projecte BigCode. Inclou informació sobre les decisions preses durant el procés i altres dades com l’empremta de carboni de l’algoritme o el que paguen a empreses externes d’etiquetatge de dades. Aquest darrer és un assumpte que ha generat molts maldecaps a empreses com OpenAI, un cop s’ha sabut que la companyia va subcontractar treballadors kenyans per menys de dos dòlars l’hora per fer que ChatGPT fos menys tòxic, és a dir, per evitar respostes violentes, sexistes i racistes.
A més de la Carta de governança de BigCode, en altres projectes com BigScience també hi ha la Carta ètica: una guia per a la presa de decisions sobre la governança del model. Confeccionar-la va ser el resultat d’una investigació sobre l’articulació entre l’ètica, la regulació i el desenvolupament tècnic en aquest tipus de projectes. “Es regeix per uns valors que han dut, per exemple, a incloure restriccions d’ús i certes obligacions dins de la llicència”, afirma l’expert. Per exemple, no es permet fer-la servir per oferir recomanacions mèdiques, i s’obliga a comunicar a cada usuari que el resultat ha estat generat per un sistema d’IA.
Per acabar, el tercer document rellevant és el que recull la documentació de tot el procés de desenvolupament del model i que està disponible en obert. “Molta gent el que vol és tenir accés al desenvolupament del model pel sol fet de saber-ho, per aprendre, per millorar-lo, avaluar-ho…”, afirma Muñoz.
Els qui (implementen)

El talent en aquest procés d’implementació és pluridisciplinar. Involucra enginyers d’aprenentatge automàtic i, dins d’aquests, especialistes en entrenament de models fundacionals, etiquetatge (científics de dades), etc. També requereix especialistes legals per dissenyar els mecanismes de govern i els termes d’ús; eticistes per assegurar un desenvolupament ètic; experts en sostenibilitat per traçar l’empremta de carboni dels algoritmes…
I què passa amb els dissenyadors i els equips d’experiència d’usuari? En projectes com BigScience o BigCode no tenen gaire presència, ja que l’objectiu no és comercialitzar els models sinó obrir-los perquè altres persones i organitzacions els facin servir. En el cas d’altres empreses amb models propietaris -com OpenAI-, aquests equips sí que juguen un paper essencial. Ho veurem amb el cas de l’empresa Narrativa, pionera en la generació de contingut automatitzat a Espanya.
“Narrativa treballa amb 55 mitjans de comunicació d’arreu del món i amb empreses de la indústria farmacèutica, la banca i el govern”, assegura el fundador i director general, David Llorente. El seu model consisteix a llicenciar la seva plataforma de IA generativa, basada en versions reentrenades de models com Flama 2 (el model LLM de codi obert de Meta).
Llorente explica que el procés de reentrenament el fan els enginyers d’aprenentatge automàtic. La seva feina és crear bons datasets sintètics. En què consisteixen? Llorente ho exemplifica amb el cas de la indústria farmacèutica. “Un problema en aquest sector és que els metges, en descriure els símptomes d’un pacient, de vegades no fan servir els termes estandarditzats”, comenta. “El que fan els enginyers d’IA és fer servir els diccionaris de la indústria juntament amb el model (encara no reentrenat) per generar variacions de la mateixa paraula”, prossegueix. Amb aquestes variacions confeccionen el dataset sintètic que després faran servir per reentrenar el model. Així, quan tingui una entrada que sigui una d’aquestes variacions o similar, podreu saber a què s’està referint i generar una sortida adequada.
A més d’aquests enginyers, quins altres perfils són clau a l’empresa? Més enginyers: sistemes, infraestructura i programadors. Són 12 persones en total. Però a més, en el cas de Narrativa, sí que és molt important l’equip encarregat de desenvolupar l’experiència d’usuari (el que es coneix com a UX) i d’optimitzar la satisfacció dels clients. Són quatre persones que s’encarreguen de dissenyar les aplicacions i interfícies que faran servir els destinataris finals per tal de garantir que compleixen les seves expectatives. També hi ha una persona encarregada de liderar el producte –la plataforma–.
“Un altre perfil clau és el de compliment legal, atès que estem treballant en indústries regulades i amb contractes privats”, assenyala Llorente. És una persona que treballa per assegurar que la plataforma i les tecnologies que la configuren estan alineades amb la regulació existent, amb aspectes com la privadesa, la ciberseguretat, la responsabilitat de cada pas en cada procés, a qui ha de reportar cada persona, etc. És un perfil equivalent al de governança a Hugging Face.
A més d’aquests equips, també compten amb dues persones per a comunicació i màrqueting. Algunes altres tasques les externalitzen. Per exemple, encara que hi ha persones especialistes en àmbits diferents (mitjans de comunicació, salut…), de vegades cal implicar experts independents addicionals. Altres vegades, codisenyen les solucions braç a braç amb els propis clients, empreses del sector que aporten aquesta expertesa.
Responsabilitat humana
Així és, grosso modo, el procés de creació, desenvolupament i implementació de sistemes algorítmics a la pràctica. Queda clar –i és important no oblidar-ho– que cada algoritme és el resultat d’una sèrie de decisions humanes. El disseny reflecteix tant les necessitats del context en què sorgeixen com les intencions i prejudicis dels creadors.

Així mateix, en els conjunts de dades d’entrenament també s’hi aprecien els biaixos dels qui seleccionen aquestes dades, els biaixos històrics que contenen i els biaixos propis del món en què operen els models. Com a conseqüència, sovint automatitzen les desigualtats i perpetuen la discriminació per raça, gènere, religió, ingressos, capacitats o tendència sexual. Creen cicles de retroalimentació que perpetuen la injustícia. I, ja que s’estan utilitzant per prendre decisions importants en molts sectors, tenen un poder creixent sobre l’acció humana, fins i tot per sobre: s’objectivitzen amb la suposada imparcialitat dels números.
Aquests sistemes amb problemes intrínsecs de classificació i biaixos són els que la matemàtica i científica de dades Cathy O’Neil anomena “armes de destrucció matemàtica”: governen l’accés i l’exclusió a la informació i a les oportunitats, jutgen i prenen decisions de forma arbitrària. A les versions més avançades són, a més, caixes negres: sistemes opacs el procés i les raons dels quals per obtenir resultats específics no són completament comprensibles per als humans. Aquesta condició és particularment important per garantir l’equitat en l’ús d’algoritme i per identificar possibles biaixos a les dades de base.
Les persones involucrades en el disseny, el desenvolupament i la implementació de models algorítmics han d’assegurar-se que no només siguin eficients i efectius, sinó també justos, explicables i ètics. Això, però, sovint no passa o es fa de forma superficial i insuficient. Sense anar més lluny, aquest mateix any Amazon (a través de Twitch), Microsoft i Meta han dut a terme retallades substantives als equips d’IA responsable i ètica, i en molts casos no només els han dissolt, sinó que també els han dispersat i atribuït altres responsabilitats. Altres com X -després de l’arribada d’Elon Musk- els han eliminat del tot, com és el cas de l’equip d’Ètica, Transparència i Rendició de Comptes que Font supervisava.
A aquests problemes s’hi afegeix el de les condicions laborals dels treballadors darrere del desenvolupament i implementació d’algoritmes i models, així com dels que es dediquen a moderar contingut sensible que al model se li ha passat per alt. Aquest darrer cas apareix, sobretot, en plataformes com les xarxes socials o YouTube.
El 2018, moderadors de Facebook van decidir demandar l’empresa per no protegir-los d’un possible trauma mental. Denunciaven ser bombardejats amb milers de vídeos, imatges i transmissions en viu d’abús sexual infantil, violació, tortura, bestialitat, decapitacions, suïcidi i assassinat. El 2020, Facebook va acordar pagar 52 milions de dòlars a 11.250 persones que exercien la feina en aquell moment o l’havien exercida prèviament.
El desenvolupament de sistemes d’intel·ligència artificial continuarà enfrontant-se a aquests reptes i a d’altres, com l’atribució de responsabilitat quan un model d’IA falla. No pot ser culpa de l’algoritme ni del model, que és un producte informàtic inert, sinó de les persones de carn i ossos que hi ha darrere de la invenció i desplegament.
Alguns d’aquests desafiaments s’aborden en regulacions ja en efecte a Europa (com la Llei de serveis digitals) o en procés d’aprovar-se, com la Llei d’IA. Són lleis –encara que imperfectes– dissenyades amb el propòsit de salvaguardar els drets de la ciutadania i de canalitzar el desenvolupament tecnològic cap al bé comú.
També s’obren oportunitats professionals en aquests àmbits: el de la regulació i la governança de la IA, i el de la cerca de nous algoritmes i models que contribueixin a lluitar contra grans reptes en matèria de salut, medi ambient, educació, desigualtat, etc. Sempre, això sí, conscients de l’abast d’aquests sistemes i dels seus límits. Conèixer en què consisteixen, com es creen, desenvolupen i implementen i qui hi ha darrere ajuda a tocar de peus a terra.
Reportatge

“Ineptitud sobrevinguda”, la nova croada contra la llibertat sindical
per Joan Cascante Agudo 23/08/2024
Proquímia, Gráficas Varias i Farré Logístics són algunes de les empreses que han optat per l’acomiadament de delegats, el que per a la UGT és un clar exemple de persecució sindical
Reportatge

Les conseqüències de la gamificació del treball
per Jordi Ojeda 08/08/2024
Així ho plasama la pel·lícula coreana 'Next Sohee' (Da-eum So-hee, 2022), estrenada l'any passat
Reportatge

Periodistes multitasca
per Ànnia Monreal 02/08/2024
A la professió, el màrqueting guanya força i la intel·ligència artificial comença a treure el cap

